FAQ
在 2.0 投影片第二頁的圖中,state 1 會有3個 observation,是因為頭兩次的 transition 都是 state 1 → state 1,這在 training 和 testing 的時候會因為 a11 比 a12 , a13 ... 都大而顯現出來。換個角度說,在 2.0 投影片第二頁的圖中,state sequence 應該是 q1q1q1q2q2q2q2q3... 。這樣看的話就很清楚每個 state 是對應到一個 observation。因此演算法中 q 和 o 的下標都是從 1 到 T 。
就長得像 model_init.txt 一樣,其中 π 向量的總和需為 1, A 矩陣的每個 row sum 和 B 矩陣的每個 column sum 也都需是 1 。
seq_model_01~05 可以想成是五個 phoneme 的 model,比方說知道以下的話只會出現ㄚ、ㄛ、ㄞ、ㄟ、ㄢ 五個音,於是就把ㄚ的 training data 合在一起 train 一個ㄚ的 model,ㄛ的 training data 合在一起 train 一個ㄛ的 model,...等等。於是有了五個 model 對應到五個 phoneme,在 testing 的時候就把 data 拿去在這五個 model 裡各求一個機率,如果是ㄟ的 model 機率最大就說答案是ㄟ。雖然現在我們沒有說 seq_model_01~05 是什麼東西,不過你可以想成 seq_model_01 是ㄚ的 training data,seq_model_02 是ㄛ的 training data 等等。
語音辨識中的 state 數目是使用者自己決定的,畢竟一個 phoneme 裡有很多 state 可說是我們因為語音連續性所做的假設。因此究竟要訂定4個還是5個 state 並不是 data dependent,而是 user dependent。使用 3~6 個 state 都是有看過的,甚至每個 model 都用不同數目的 state 理論上也是有可能的 (雖然實際上很少人這樣做) 。不過一但決定好,在 training/testing 流程中就不會再改變,因為演算法都是在假設 state 數目已知的情況下運作的。在這個作業中只需要像 model_init.txt 裡一樣假設有 6 個 state 就好 (因此 A 是 6*6 矩陣,π是 1*6 向量)。至於初始機率,只要滿足適當的限制 (如 A 矩陣的每個 row sum 是 1 ) 即可,在 training 的 iteration 次數夠多的情況下應不至於對結果有太大的影響。
用 seq_model 去統計當做初始值當然也是可以的,其實在語音辨識中,因為 B 的參數變成 Gaussian 的 mean 和 variance,它們的值無範圍限制難以隨便假設,此時有一種設定初始值的方法就是去算所有 observation 的 global 平均。然而即使如此也無法分開 state 估計,每個 state 的初始值只能都設一樣, Aij 的初始值也無法估計只能任意假設。所以終究還是要跑 training algorithm。而在跑過之後收斂到的結果雖然會跟初始值有關,但是我們無法知道哪個初始值會產生較好的結果。在作業中也可以嘗試不同的初始值,看看結果的差異。
在每一行有幾個字母就是幾個觀測值,建議不要寫死,寫成讓程式讀出觀測值的個數比較好。觀測值的個數並不用固定,training 和 testing 可以用不同的個數,甚至 training 裡頭或 testing 裡頭也可以每筆資料有不同的個數。以語音辨識為例,觀測值的個數相當於錄音的長度。雖然也許可以硬性規定每筆聲音資料都錄一樣長,但是這相當麻煩,實際上不需要假設每筆資料都一樣。在作業裡為了方便所以才會都是50個。
對每個 state i 和 時間 t ,你的程式都會算出 γt(i),而 update B 矩陣的分子部分,是要把不同 observation 的 t 的 γt(i)累積起來。舉例來說如果 observation 是 AABCCBFFAEDD...,那麼 update bi(A) 的分子部分就是 γ1(i) + γ2(i) + γ9(i) + ...,update bi(B) 的分子部分就是 γ3(i) + γ6(i) + ... 等等。
寫 makefile 的用意代表要在 Linux command line 下執行,不過這不代表一定要在自己的電腦灌 Linux,可以登入工作站執行。資訊系的人可登入 linux4.csie.ntu.edu.tw ;若都沒有工作站帳號的同學可至資訊系館 217 申請帳號。登入的介面可以使用 pietty 或 putty 或其他 ssh 連線軟體。從 Windows 上傳檔案到工作站上可使用 CuteFTP, FileZilla, gFTP, WinSCP 或其他支援 ssh 的 FTP 軟體。 Linux 下的基本指令操作可參考鳥哥,應該只需學會簡單的複製移動檔案指令就夠用了。在 Linux 下並非以副檔名而是以權限作為能否當作執行檔的依據。 Makefile 的作用就是從 C 的 source code 製造出執行檔。作業壓縮檔裡的 Makefile 不用看懂,只需要執行 make 指令就會自動把 test_hmm.c 這個程式 compile,產生 test_hmm 這個執行檔。要執行時就用 ./test_hmm 指令。可以參考投影片第 19 頁。如果不想用 test_hmm 作為檔名,只要把 Makefile 裡的 TARGET=test_hmm 那行改成 TARGET=你想要的檔名。
如果不想在工作站上做,也可以使用一種在 Windows 下模擬 Linux 環境的程式,叫做 Cygwin
那段是介紹如何用 load_models 和 dump_models 這兩個函數,它們能一次讀取和印出 5 個名稱列在 modellist.txt 的 model,當然這 5 個 model 要都已經存在於資料夾中。你可以複製幾個 model 檔然後觀察他的效果。
每一行代表一筆 sample,但是 training 時每次 update 都是把每一筆 training data 的 γ 和 ε 累加起來,相當於 4.0 投影片 update A, B 的公式,分子分母外面都多一層Σ,因此在投影片 16 頁的Σ不只是對每個 t ,也是對每筆 sample 的 γ, ε 做加總,所以公式應修正如下 :
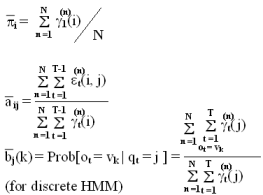
testing_data.txt 有一個對應的 testing_answer.txt,要計算出你 Viterbi 得到的答案跟 testing_answer.txt 有百分之多少一樣,那就是正確率 (accuracy),要寫在報告裡 (或是計算有百分之多少不一樣,即錯誤率)。而 testing_data2.txt 沒有給正確答案,所以只要附上你得的答案就好。
這是助教跑的 accuracy 結果,橫軸是 iteration 次數。

其實要 make 兩個檔案很簡單,改成:
.PHONY: all clean CFLAGS+= LDFLAGS+=-lm # link to math library TARGET=test_hmm train test all: $(TARGET) # type make/make all to compile test_hmm clean: $(RM) $(TARGET) # type make clean to remove the compiled file